
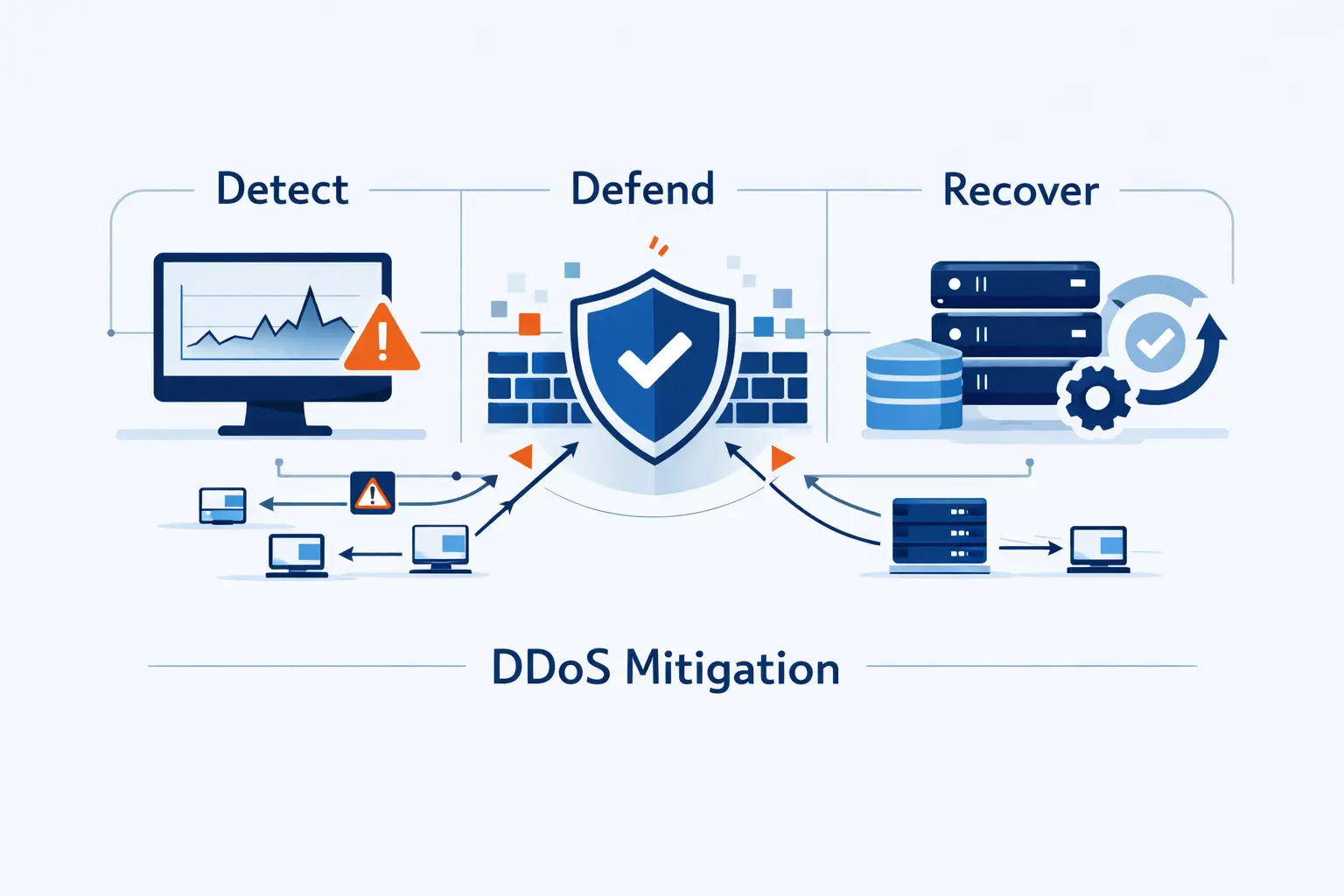
- What DDoS Mitigation Is and Why It Matters
- How DDoS Attacks Work
- The Main Types of DDoS Attacks
- The Core Stages of DDoS Mitigation
- DDoS Mitigation Techniques That Form a Layered Defense
- Cloud-Based, On-Premises, and Hybrid DDoS Mitigation
- How to Choose a DDoS Mitigation Service
- Architecture Best Practices for DDoS Resilience
- How to Prepare Before a DDoS Attack
- Responding to a DDoS Attack and Recovering Afterward
- How to Test and Improve Your DDoS Mitigation Strategy
- DDoS Mitigation FAQ
- How 1Byte Supports Website and Cloud Infrastructure Needs
- Conclusion: Building a Stronger DDoS Mitigation Strategy
At 1Byte, we see ddos mitigation as one of the clearest tests of whether internet infrastructure is built for the real world. A website can look great in staging and still fail when traffic turns hostile. An API can pass every feature check and still fall over when connection tables, edge links, or application workers get swamped. In our view, the job is simple to describe and hard to execute. We must keep legitimate users connected, block malicious traffic fast, and recover with fewer blind spots than we had before.
What DDoS Mitigation Is and Why It Matters
We think DDoS mitigation belongs in the same conversation as uptime, backups, and incident response. It is not a niche security add-on. It is core operations. The business stakes keep rising as Gartner expects global IT spending to reach $6.31 trillion in 2026, which tells us just how much revenue and trust now sit behind internet-facing systems.
FURTHER READING: |
| 1. How to Choose Keywords for SEO in 2026 |
| 2. DNS Propagation: What It Is, How It Works, and How to Check It |
| 3. Cloud API Security Best Practices for Modern Cloud Applications |
1. The Primary Goal of Keeping Services Available
The first goal is availability. That means real users can still load pages, submit forms, call APIs, log in, and finish checkouts while an attack is in progress. Good ddos mitigation does not chase perfect cleanliness. It protects the paths that matter most and keeps the service usable long enough for deeper controls to kick in.
2. How DoS and DDoS Differ
A DoS attack comes from one source or a small set of sources. A DDoS attack is distributed, which means the traffic comes from many systems at once. That difference matters. A single noisy source is often easy to block. A distributed wave can look like ordinary traffic at first, especially when it hits from many networks, regions, and device types.
3. The Cost of Downtime, SLA Failures, and Reputation Damage
Downtime hurts in layers. We lose direct revenue first. Then support queues fill up, service level agreement commitments get missed, and customers start wondering if the next outage will be worse. In our experience, reputation damage often outlasts the attack itself. People forgive bad luck faster than they forgive visible fragility.
How DDoS Attacks Work
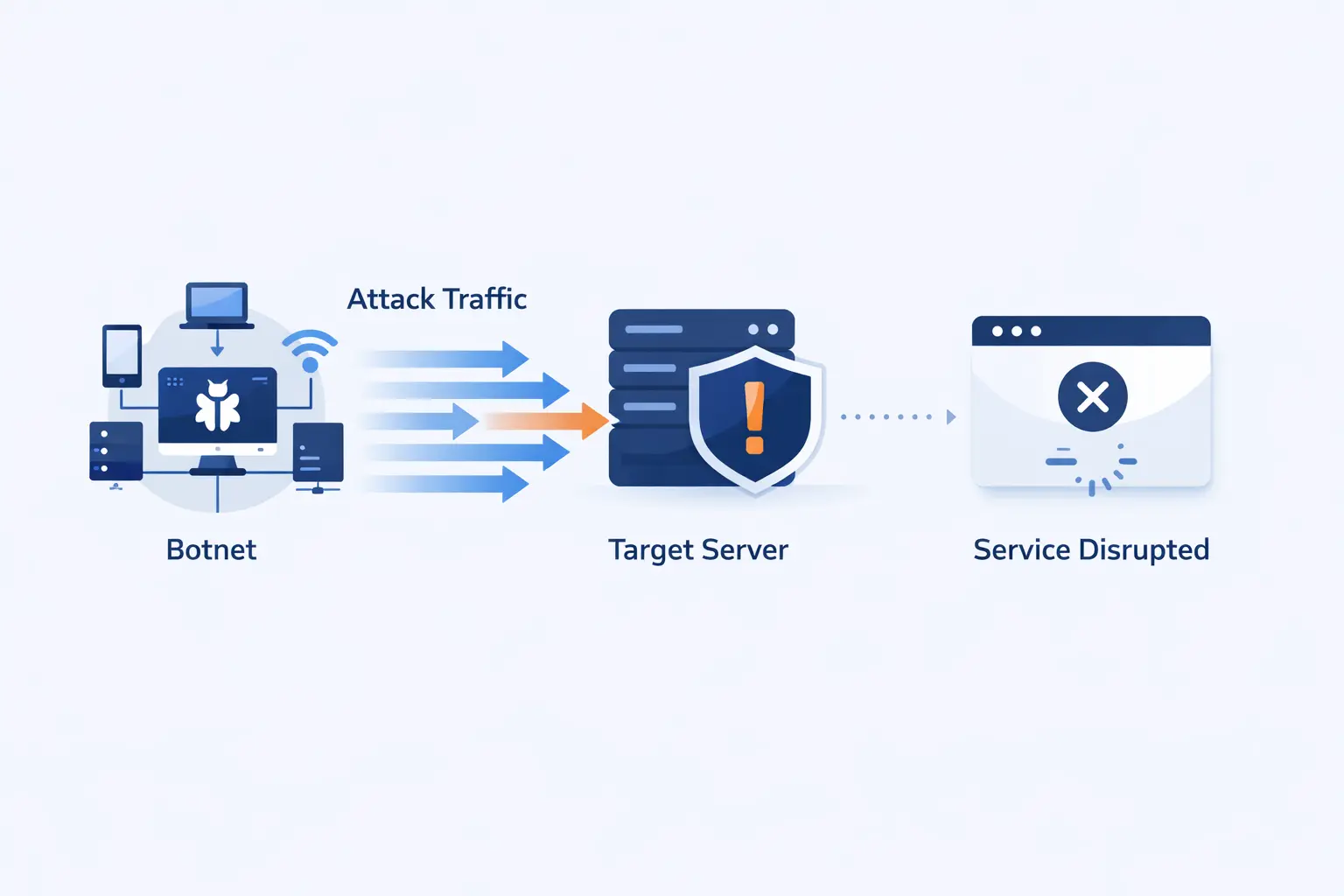
Most attacks follow a basic idea. The attacker finds the cheapest way to exhaust something expensive on the defender’s side. That bottleneck might be bandwidth, packets per second, new connections, CPU, memory, TLS handshakes, cache misses, or database work. Once we see the attack that way, the defense becomes easier to reason about.
1. Botnets, Spoofing, Reflection, and Amplification
Attackers often rely on botnets, which are many compromised devices acting together. They may also forge source IP data to enable reflection and amplification. That is why the IETF published guidance focused on spoofed source addresses. Reflection tricks third-party systems into replying to the victim, and amplification makes each small request trigger a much larger response.
2. Why Attackers Target Network, Transport, and Application Layers
Different layers fail in different ways. Network and transport layer attacks try to saturate links or overwhelm stateful devices such as firewalls and load balancers. Application layer attacks aim higher up the stack. They try to burn CPU, worker threads, cache capacity, or database queries with requests that can look almost normal.
3. Why Multivector Attacks Are Harder to Mitigate
Multivector attacks are harder because they force defenders to solve several problems at once. One wave may flood the edge. The next may target login endpoints. Another may hammer DNS. If we stop only one vector, the attacker can pivot. That is why we prefer layered controls with shared visibility across network, platform, and application teams.
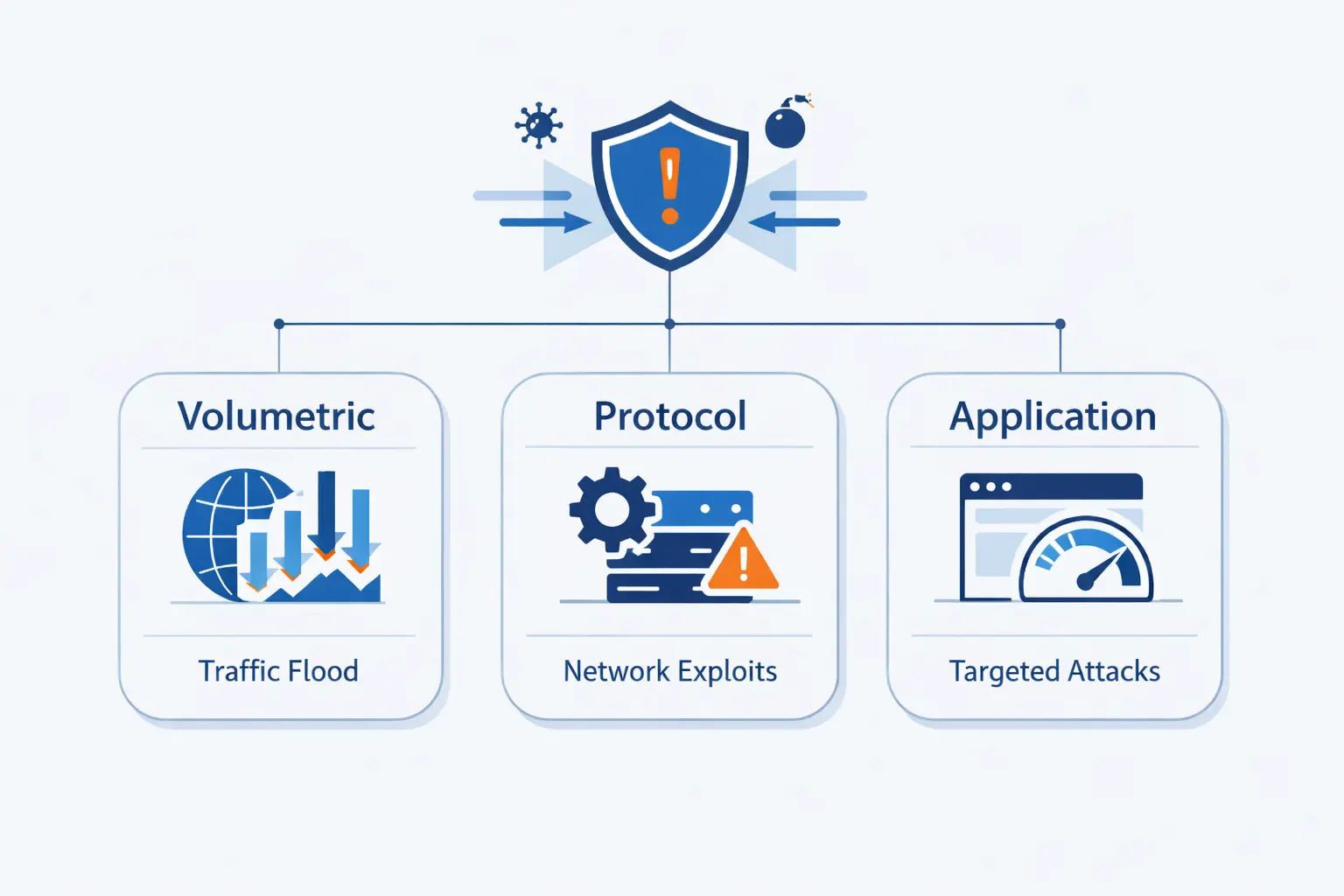
The Main Types of DDoS Attacks
Real attacks rarely fit neatly into one textbook box. GitHub’s 2018 incident peaked at 1.35 Tbps, which is a useful reminder that theory turns into live operations very quickly once traffic spikes and routing decisions must happen in minutes.
1. Volumetric Attacks Such as UDP Floods and DNS Amplification
Volumetric attacks try to consume raw bandwidth or packet-processing capacity. UDP floods are blunt instruments. DNS amplification is sharper. It uses small requests to trigger larger responses from exposed services. We usually spot these attacks through sudden jumps in ingress traffic, packets per second, and abnormal source distribution.
2. Protocol Attacks Such as SYN Floods and Smurf Attacks
Protocol attacks abuse how network protocols work. SYN floods target the connection setup process and try to exhaust state tables before real sessions can form. Smurf attacks are older, but they still teach the right lesson. Protocol behavior itself can be abused when network devices trust traffic too freely or keep too much state open.
3. Application Layer Attacks Such as HTTP Floods and DNS Query Floods
Application layer attacks are often the most frustrating because they can look legitimate. An HTTP flood may hit expensive pages, search endpoints, or login flows. A DNS query flood can burn resolver or authoritative capacity. These attacks do not always need massive bandwidth. Sometimes they win by forcing expensive work over and over again.
4. Multivector Attacks That Shift Across Layers
A determined attacker does not stay polite. They may start with a UDP surge, then switch to SYN floods, then move to HTTP requests that mimic browsers. That shift is exactly why we do not trust a single device or a single rule set. Each layer needs its own controls, and those controls need to work together.
The Core Stages of DDoS Mitigation
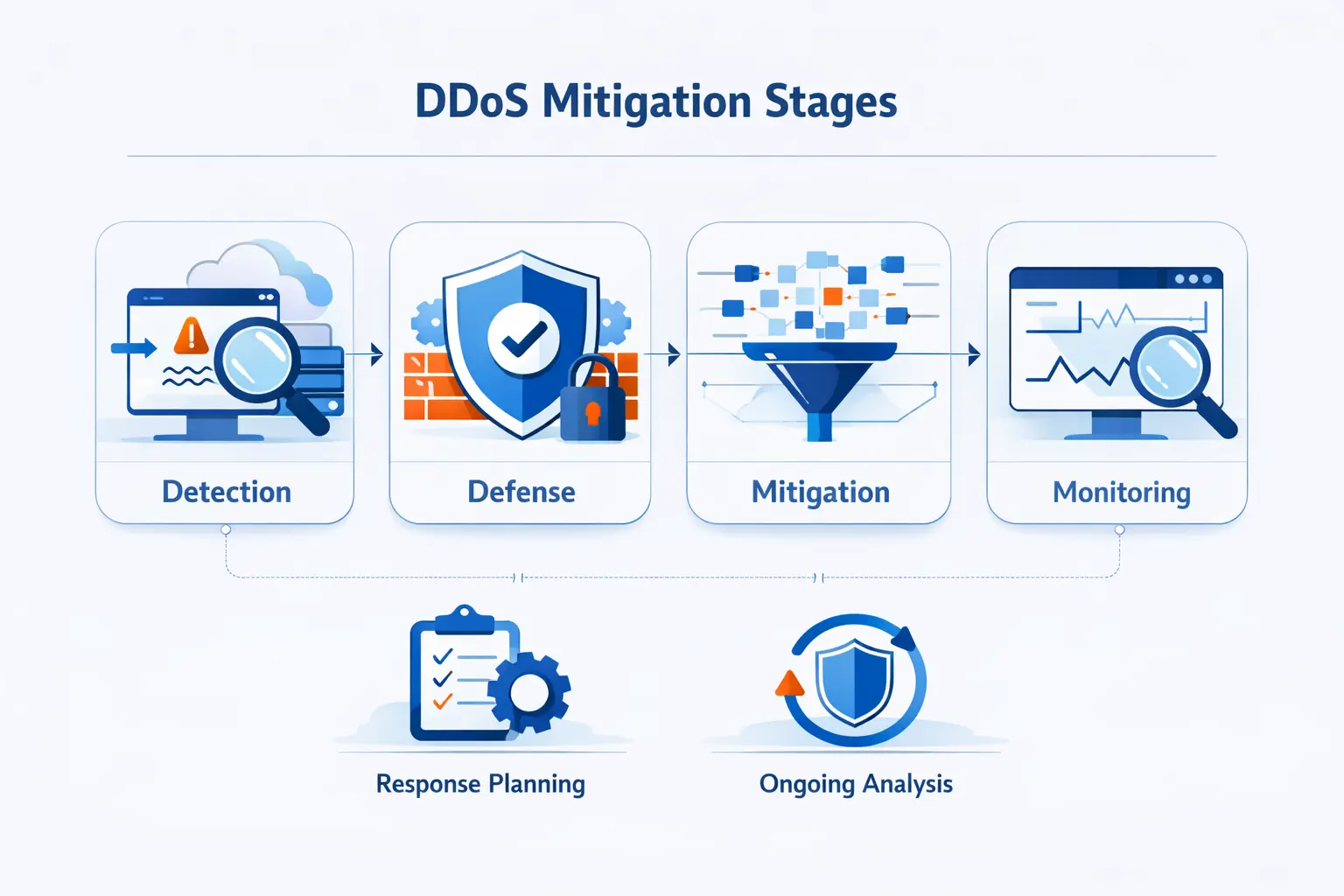
We like to frame ddos mitigation as a cycle rather than a product. First we detect. Then we filter and reroute. After that, we measure the damage, learn from it, and tighten the next response. Teams that treat mitigation as a one-time purchase usually find out the hard way that attackers adapt faster than static playbooks.
1. Detection and Traffic Baselining
Detection starts long before an incident. We need a baseline for normal traffic, including requests per second, packets per second, connection rates, top URLs, cache hit patterns, and geographic mix. In GitHub’s 2018 incident, monitoring caught an anomaly in the ratio of ingress to egress traffic, which is exactly the kind of signal mature teams watch for.
2. Response Through Filtering, Scrubbing, and Bot Detection
Once an attack is confirmed, response becomes a sorting problem. We filter obvious garbage, challenge suspicious clients, scrub dirty traffic upstream, and look for request patterns that separate people from bots. The goal is not to inspect every packet forever. It is to cut the attack down fast enough that the application can breathe again.
3. Routing, Rerouting, and Traffic Distribution
Routing changes are often what save the day. We may steer traffic to a scrubbing provider, withdraw certain announcements, or spread load across more edge locations. In GitHub’s case, traffic was moved to Akamai by changing BGP announcements so the service could use more edge capacity during the attack.
4. Analysis, Adaptation, and Continuous Improvement
After the pressure drops, the work is not over. We review what matched, what slipped through, what was blocked incorrectly, and where visibility was thin. Then we tune thresholds, update rules, adjust runbooks, and decide which bottleneck needs to be moved farther away from the public edge next time.
DDoS Mitigation Techniques That Form a Layered Defense
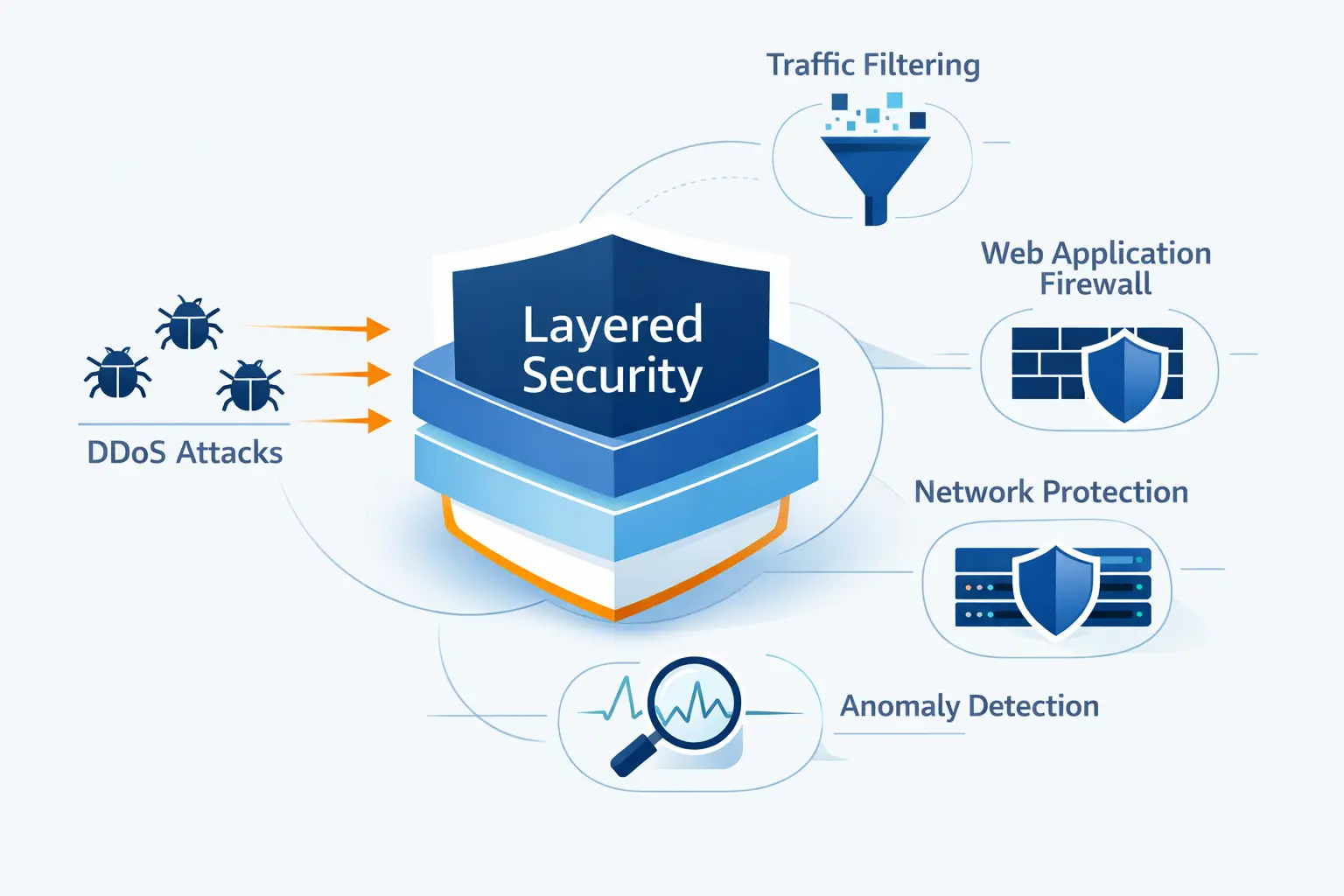
At 1Byte, we do not believe in silver bullets here. A layered defense works because each control handles a different failure mode. The edge absorbs. The WAF inspects. Rate limits slow abuse. Load balancers spread healthy traffic. Scrubbing cleans what cannot be trusted yet. That mix is what gives us room to maneuver.
1. Rate Limiting, Protocol Filtering, and Access Control Rules
Rate limiting is one of the cleanest controls because it caps abuse without depending on perfect signatures. AWS explains that a rate-based rule rate limits requests when they arrive too fast according to our criteria. We usually pair that with protocol filtering, IP sets, and allow rules for trusted systems.
2. Traffic Scrubbing, Sinkholing, and Blackhole Routing
Scrubbing sends suspect traffic to specialized infrastructure that removes malicious packets and forwards clean traffic onward. Sinkholing diverts traffic to a controlled destination for analysis or safe discard. Blackhole routing is the blunt tool of last resort. It can protect upstream infrastructure, but it also drops good traffic, so we use it carefully.
3. Web Application Firewalls, Load Balancing, and Content Delivery Networks
A WAF helps with HTTP and API abuse because it can inspect requests at the application level. Load balancers spread healthy demand. CDNs cache static assets and reduce origin exposure. Google’s documentation shows how global proxy load balancers can work behind a single, anycast IP address, which is exactly the kind of edge distribution that helps during pressure events.
4. Anycast, Edge Filtering, and Auto Scaling
Anycast helps absorb traffic closer to where it enters the internet. Edge filtering drops obvious junk before it reaches the origin. Auto scaling can add capacity for real demand or moderate spikes, but we never treat it as a complete answer. If the attack is big enough, adding more app servers just means we are paying more to stay uncomfortable.
Cloud-Based, On-Premises, and Hybrid DDoS Mitigation
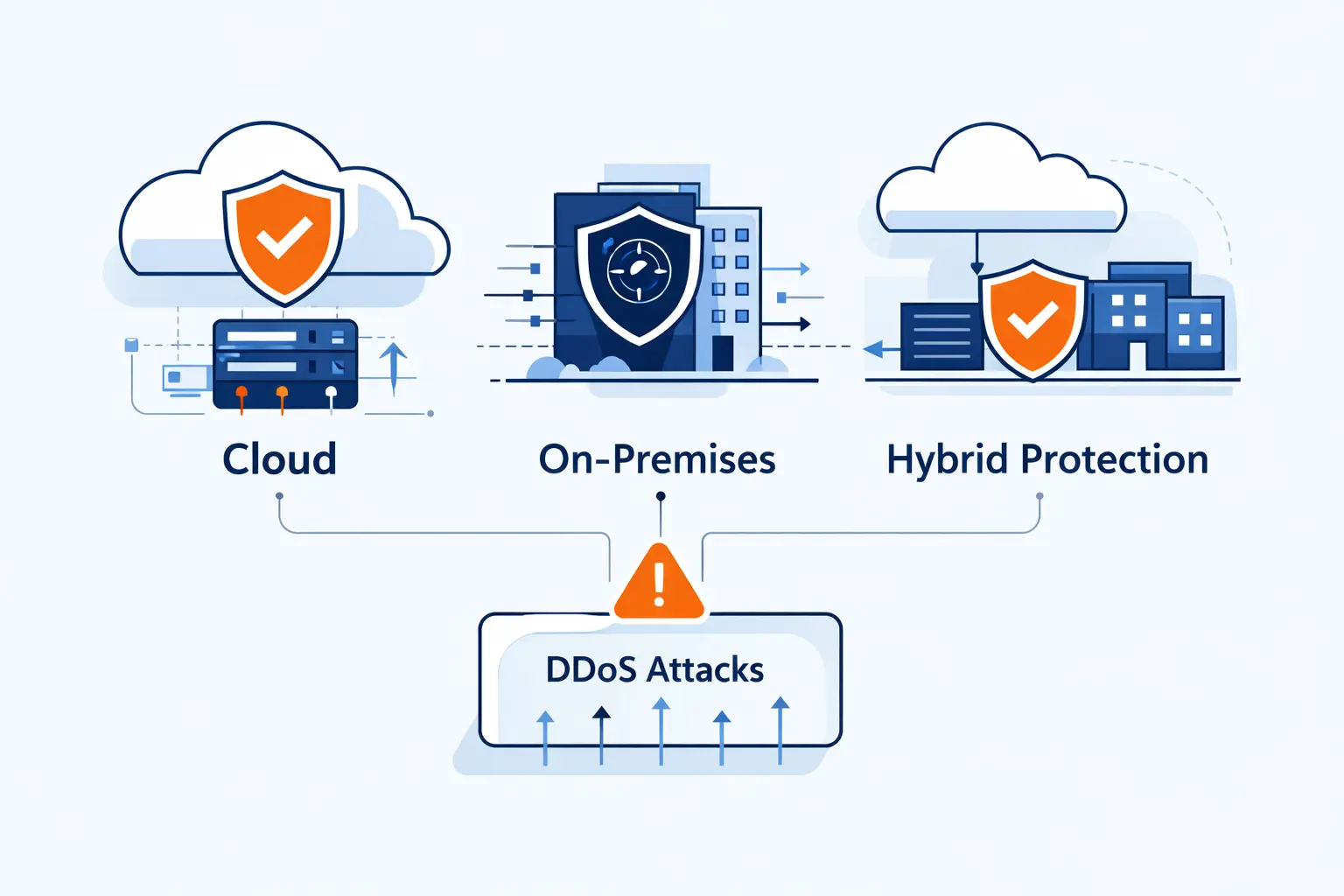
Architecture choices matter more every year because workloads keep shifting outward. IDC expects public cloud spending to surpass $1 trillion in 2026, and that tells us something simple. More critical services now live behind public endpoints, so protection has to scale with cloud-era exposure.
1. When On-Premises Appliances Make Sense
On-premises appliances still make sense in some cases. They can be useful for low-latency filtering, strict internal control, regulated environments, or private services that should never hairpin out to a third party first. The downside is fixed capacity. If the attack outgrows the box, the box loses. Physics does not negotiate.
2. Why Cloud-Based Mitigation Handles Larger Attacks
Cloud-based mitigation works best when the attack is larger than what local hardware can absorb. Distributed edge networks, upstream scrubbing, and wide routing footprints let providers handle traffic before it reaches a customer’s narrowest links. In our view, this is why cloud mitigation is often the practical answer for public-facing websites and APIs.
3. How Hybrid Models Balance Local Control and Elastic Capacity
Hybrid models split the problem sensibly. Local controls handle smaller attacks, policy enforcement, and sensitive workloads. Cloud capacity handles overflow and big volumetric events. We like this model for many mid-sized businesses because it preserves control where it matters and adds breathing room where local infrastructure is weakest.
How to Choose a DDoS Mitigation Service
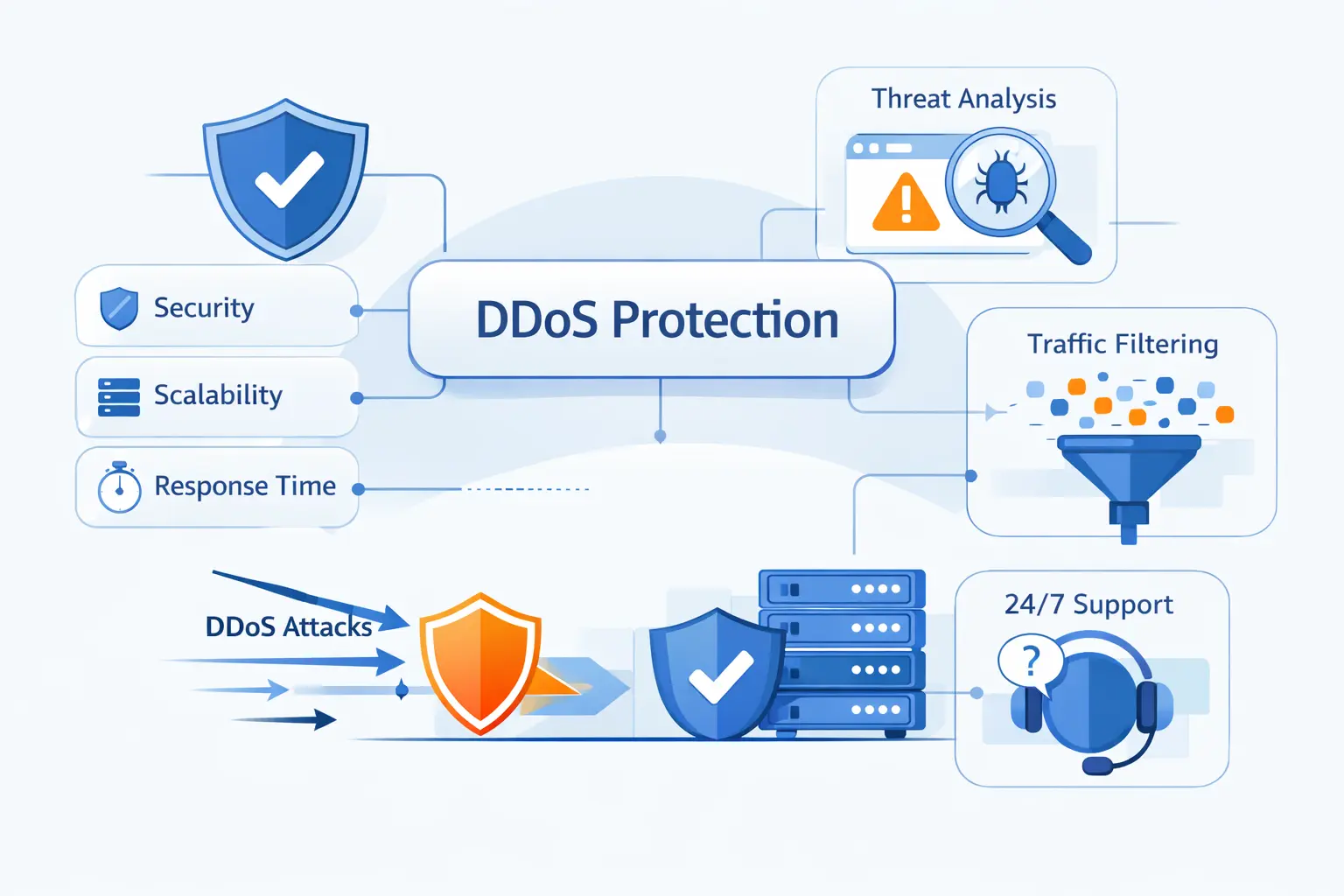
Buying a service without asking architecture questions is a mistake. We prefer to judge providers by how they handle ugly moments, not polished demos. The right partner should help us see traffic clearly, make routing decisions quickly, and fail in predictable ways when a plan needs to change under stress.
1. Network Capacity, Processing Capacity, and Scalability
Ask what the provider can actually absorb, inspect, and forward. Bandwidth alone is not enough. We also care about packets per second, connection handling, TLS processing, Layer 7 inspection, and the ability to protect APIs separately from websites. A big number on a landing page means little if the wrong bottleneck fails first.
2. Flexibility, Reliability, Redundancy, and Failover
Good services give us choices. We want multiple edge locations, diverse upstream paths, tested failover, and deployment models that fit our stack. We also want clean integration with DNS, load balancers, WAF policies, and observability tools. If every change requires a ticket and a wait, the service is slower than the attacker.
3. Time to Mitigation, Traffic Visibility, and 24/7 Support
Time to mitigation matters because every extra minute lands on users. We want dashboards, logs, event timelines, and people who answer fast when the incident starts. In our experience, support quality is one of the biggest separators between providers. Fancy controls are nice. Calm, competent humans at 2:00 a.m. are nicer.
Architecture Best Practices for DDoS Resilience
We build resilience by shrinking the blast radius. That means reducing single points of failure, hiding origin systems when possible, and making sure DNS, edge, and application layers do not all collapse from the same bad assumption. The strongest setups are rarely flashy. They are disciplined.
1. Protect DNS, Edge, and Application Entry Points
If DNS fails, the application may as well be perfect and invisible. If the edge fails, the origin never gets a chance. If login, search, or API gateways fail, the business still feels down. We protect those entry points first because they are the first levers an attacker will pull and the first complaints customers will notice.
2. Use Source Address Filtering to Reduce Spoofing and Amplification
Source validation is one of those ideas that seems obvious because it is. The old IETF guidance on ingress filtering was written to stop attacks that rely on forged packets, and it remains relevant because spoofing still enables reflection and amplification. Where networks apply those checks well, attackers lose room to maneuver.
3. Combine WAF Policies, Load Balancers, DNS, and Network Controls
We get the best results when controls overlap without duplicating each other blindly. WAF rules protect expensive application paths. Load balancers spread healthy demand. DNS steers users toward working edges. Network controls deal with packet abuse early. The Google and AWS guidance points in the same direction. Distribution and selective filtering work better together than alone.
How to Prepare Before a DDoS Attack
Preparation is where most wins begin. By the time a flood is obvious to customers, the clock is already against us. We want the first minutes to feel rehearsed, not improvised. That means baselines, asset lists, contact paths, and pre-approved traffic changes should exist before anyone is staring at dashboards in a panic.
1. Baseline Normal Traffic and Monitor for Early Warning Signs
Baselines should cover more than bandwidth. We watch request rates, connection attempts, handshake failures, top endpoints, cache hit ratios, geographic spread, and user-agent patterns. Early warning often comes from strange combinations, not one giant spike. That is why anomaly detection works best when we understand what normal busy traffic already looks like.
2. Conduct Risk Assessments and Identify Critical Assets
Not every service deserves the same response path. We identify what keeps revenue flowing and what keeps operations recoverable. That usually includes DNS, identity systems, API gateways, checkout paths, customer portals, admin access, and monitoring itself. If we do not rank assets before an incident, we end up arguing about priorities during one.
3. Build a Response Plan With Roles, Communications, and Escalation Paths
NIST describes incident response as a capability for rapidly detecting incidents, minimizing loss, and restoring services. We agree. A useful plan names who owns filtering, who talks to providers, who updates customers, who approves routing changes, and when leadership gets pulled in. Clear roles save minutes, and minutes save uptime.
Responding to a DDoS Attack and Recovering Afterward
When an attack starts, our priorities narrow fast. Keep the service reachable if we can. Protect the most critical paths first. Escalate early instead of late. Preserve enough evidence to learn afterward. The temptation is to throw every block rule at the problem. We try to stay more deliberate than that.
1. Work With ISPs, Cloud Providers, and Managed Security Teams
Large events are rarely solved by the application team alone. We need upstream providers, edge platforms, and sometimes managed security teams to act in sequence. GitHub’s incident is a good example. Their team quickly moved traffic to outside edge capacity, which shows why prebuilt provider relationships matter before the emergency starts.
2. Measure Service Impact, Review Logs, and Confirm Recovery
Recovery is more than seeing attack traffic drop. We confirm latency, error rates, login success, API performance, queue depth, and synthetic checks. We also review what users actually experienced. NIST’s guidance is helpful here because incident handling includes not just containment but service restoration and lessons learned after the event.
3. Upgrade Rules, Close Gaps, and Strengthen Future Defenses
Every serious event should change the environment somehow. We may tighten rate limits, shield a noisy endpoint, reduce open UDP exposure, update runbooks, or improve alerting. If spoofing or reflection played a role, network filtering deserves another look as well. A good post-incident review does not just explain the outage. It makes the next one smaller.
How to Test and Improve Your DDoS Mitigation Strategy
Testing is where confidence becomes evidence. Many teams say they have mitigation until the first incident shows that a rule was never deployed, a contact was outdated, or a failover path was theoretical. We prefer calm drills, small controlled traffic tests, and repeated review over last-minute heroics.
1. Validate Scrubbing, Rate Limits, and Filtering Rules
Validation should cover the exact controls we expect to use during a live event. That means checking whether scrubbing is reachable, whether rate limits hit the right paths, and whether filters can be activated without knocking out good traffic. A tabletop exercise is useful. A small controlled technical test is better.
2. Watch for False Positives, False Negatives, and Performance Trade-Offs
Overly aggressive controls can block mobile carriers, shared office IPs, search crawlers, partner systems, or bursty but valid customers. Weak controls let attack traffic slip through. There is always a trade-off. We think the mature approach is to measure that trade-off openly instead of pretending a rule can be strict, invisible, and perfect at once.
3. Use Continuous Monitoring, Metrics, and Simulations to Refine Policies
Metrics keep us honest. We watch time to detection, time to mitigation, blocked-versus-allowed outcomes, origin resource use, cache behavior, and recovery time after controls are relaxed. Simulations help us find policy drift early. The best runbooks age badly unless we exercise them.
DDoS Mitigation FAQ
We hear the same practical questions from small site owners, growing SaaS teams, and larger infrastructure operators. Here are the short answers we find most useful when people want clarity before they want jargon.
1. What Is DDoS Mitigation?
DDoS mitigation is the set of steps, tools, and response processes used to keep services available during a distributed denial-of-service attack. It usually includes detection, filtering, rate limiting, scrubbing, rerouting, and post-incident tuning.
2. What Does DDoS Mean?
DDoS stands for distributed denial of service. “Distributed” means the attack traffic comes from many systems at once, which makes blocking and tracing harder than a one-source denial-of-service attack.
3. What Are the Stages of DDoS Mitigation?
The usual stages are preparation, detection, active response, traffic steering, recovery, and review. We often simplify that to baseline, block, route, restore, and learn.
4. How Does DDoS Mitigation Work?
It works by identifying malicious traffic patterns, limiting or filtering suspicious requests, absorbing or cleaning traffic upstream, and keeping critical services reachable while the attack is underway.
5. What Are the Main Types of DDoS Attacks?
The main categories are volumetric attacks, protocol attacks, application layer attacks, and multivector attacks. Each targets a different bottleneck, so each needs slightly different defenses.
6. Can a Firewall Stop a DDoS Attack?
A firewall can help with smaller events and some protocol or application-layer abuse. By itself, it is rarely enough for large distributed floods. Firewalls are part of the defense stack, not the whole stack.
How 1Byte Supports Website and Cloud Infrastructure Needs
At 1Byte, we try to keep the practical side in view. Many businesses do not start with a dedicated mitigation platform. They start with a website, a domain, a certificate, a hosting plan, and the need to stay online. That is where good foundations matter.
1. Domain Registration, SSL Certificates, and Website Security Essentials
We see domain control, DNS hygiene, and TLS as the front door of resilience. If ownership records are messy or certificates are neglected, recovery gets harder fast. Basic website security still matters here too, including least-privilege access, patching, backups, and careful exposure of admin surfaces.
2. WordPress Hosting and Shared Hosting for Website Needs
For many sites, especially content sites and small business pages, reliability starts with sensible hosting choices. Shared hosting can be a practical entry point for lighter workloads. WordPress hosting makes more sense when the CMS is central and the team wants cleaner management, updates, caching, and operational guardrails around it.
3. Cloud Hosting, Cloud Servers, and AWS Partner Support
As needs grow, we believe cloud hosting and cloud servers open better paths for segmentation, observability, custom rules, and layered edge controls. For teams moving deeper into cloud architecture, AWS partner support can help connect infrastructure design with security, routing, and recovery planning instead of treating them as separate projects.
Conclusion: Building a Stronger DDoS Mitigation Strategy
DDoS mitigation is not a checkbox, and it is not a single appliance. It is a discipline. We detect earlier, filter smarter, route faster, and recover with better notes than last time. That is the real loop.
At 1Byte, our view is straightforward. Start with visibility. Add layered controls. Protect DNS, edge, and application entry points together. Rehearse the ugly moments before they arrive. When we do that well, we are not just surviving attacks. We are building infrastructure that users can trust when it matters most.