
- How DDoS attacks work
- Why DDoS prevention matters
- Know your service, defenses, and traffic baseline
- How to detect a DDoS attack early
- How to prevent DDoS with attack surface reduction
- How to prevent DDoS with filtering and mitigation tools
- Infrastructure and hygiene practices that strengthen DDoS defense
- How to choose the right DDoS protection provider
- How to prevent DDoS with a tested response plan
- What to do after a DDoS attack
- FAQ
- How 1Byte supports website resilience as a cloud computing and web hosting provider
- Final thoughts on how to prevent DDoS attacks
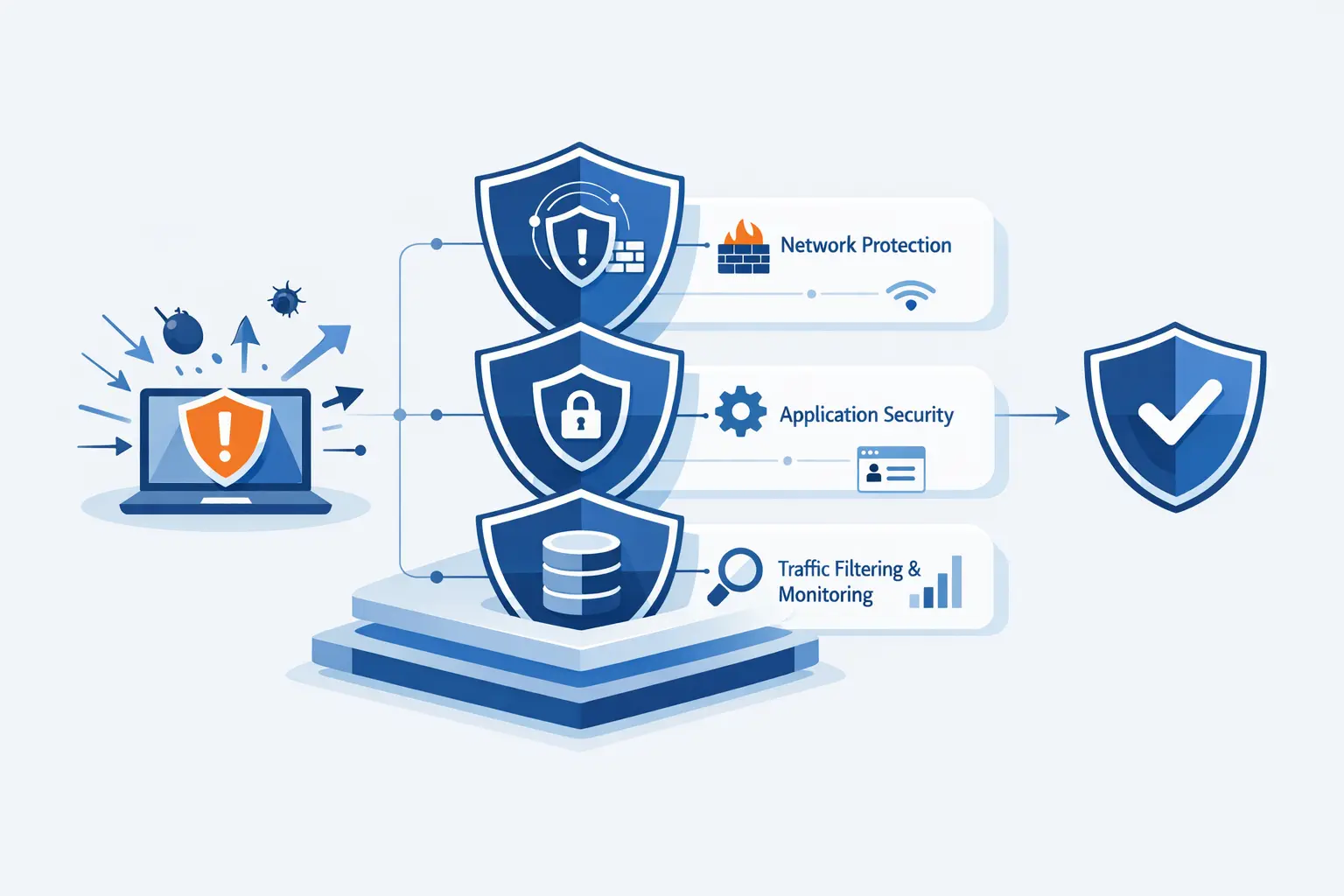
At 1Byte, we believe learning how to prevent DDoS attacks is part of basic website resilience, not a luxury reserved for giant platforms. A distributed denial-of-service event is an availability attack: the goal is to overwhelm bandwidth, connection handling, or application work until real users cannot get through. Availability is part of the product customers buy, even when they never say it out loud. From our perspective as a cloud computing and web hosting provider, the most dependable answer is layered defense rather than a single product box.
From a market perspective, Gartner projected information security spending to reach $213 billion in 2025, which tells us resilience budgets are moving from a specialist line item toward a board-level concern. That shift matters because availability work often competes with more visible product projects until an outage changes the conversation.
Meanwhile, NETSCOUT reported more than eight million DDoS attacks worldwide in the second half of 2025. For us, that is the clearest sign that DDoS is no longer an occasional nuisance; it is an operational pattern that modern websites, APIs, and hosting environments must be designed to absorb.
How DDoS attacks work
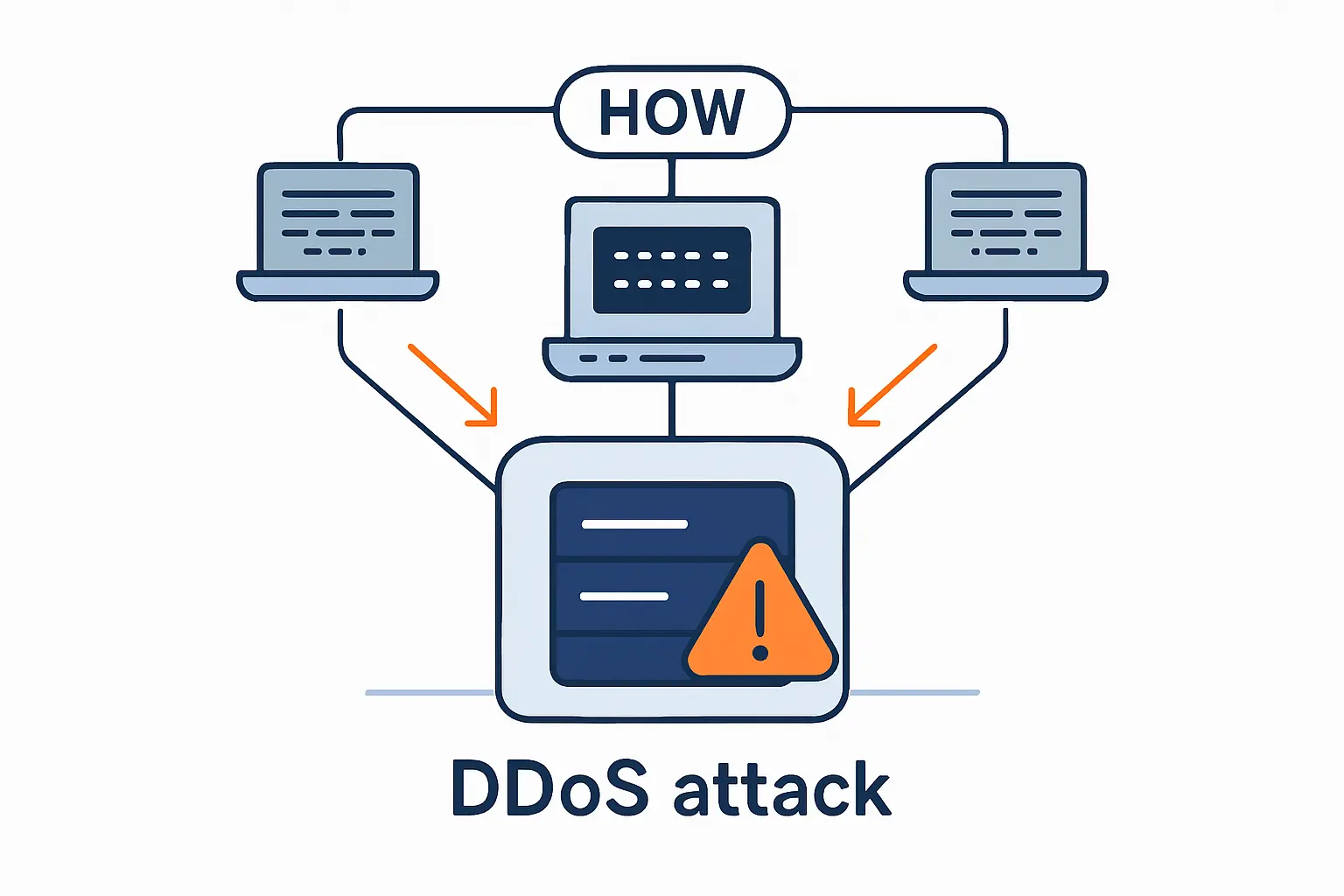
Before we talk controls, we need a plain-English model of the problem. DDoS attacks overwhelm something finite such as network bandwidth, connection tables, CPU cycles, memory, or expensive application logic. Once we identify the exhausted resource, the right mix of caching, filtering, load distribution, and upstream mitigation becomes much easier to choose.
FURTHER READING: |
| 1. What Is CVV2 Security Code Used For and Is It Safe to Share? |
| 2. 10+ Best DMCA Ignored Hosting Services for Your Website [2026 Roundup Review] |
| 3. 9 DMCA Ignored Countries in 2026 |
1. Botnets and malicious traffic floods
Botnets are fleets of compromised devices or rented attack nodes that can all send requests at once. Some are made of infected cameras, routers, and other IoT gear, while others rely on abused cloud instances or DDoS-for-hire services. From our perspective, the business risk is simple: malicious traffic rarely arrives as one obvious attacker. Instead, it shows up as many small streams that collectively overwhelm what looks, at first glance, like ordinary demand.
Coverage of the Dyn incident reported that the disruption came from 100,000 infected devices, which is a vivid reminder that consumer hardware can become attack infrastructure when basic security is ignored. When traffic is that distributed, simple blocklists fail fast and upstream mitigation becomes essential.
2. Volumetric, protocol, and application layer attacks
Volumetric attacks try to saturate bandwidth. Protocol attacks go after the machinery of the network stack, such as SYN queues, fragments, or connection tables. Some amplification attacks abuse open services so a tiny spoofed request produces a much larger reply toward the victim. Application-layer attacks stay closer to normal user behavior, which makes them especially troublesome because they can target costly pages like login, search, checkout, or API endpoints without needing absurd bandwidth.
GitHub reported an amplification event that peaked at 1.35Tbps via 126.9 million packets per second. To us, that example captures the brutal speed of modern floods: a service can move from normal to degraded before a manual response chain has even finished waking up.
3. Why multi-vector attacks are harder to stop
Multi-vector attacks are harder because the attacker does not bet on a single weakness. One wave may saturate links, another may exhaust connection handling, and a third may hammer application paths that force database work. As soon as a defender tunes for one pattern, the traffic mix can shift. That cat-and-mouse dynamic is why we prefer layered controls that watch bandwidth, protocols, and application behavior together rather than in separate silos.
Why DDoS prevention matters
Availability problems hit businesses in places that are easy to underestimate. Lost sessions, abandoned carts, delayed transactions, noisy support queues, and customer doubt can all arrive long before a team declares a formal outage. In our view, DDoS prevention matters because the business impact compounds across revenue, operations, and trust.
1. Downtime, lost revenue, and reputational damage
Uptime Institute found that 54% of respondents said their most recent significant, serious or severe outage cost more than $100,000, which is enough to reframe downtime as a financial event, not just a technical inconvenience. For smaller companies, the absolute figure may differ, but the pattern is the same: every period of unavailability burns money, attention, and goodwill.
2. SLA risk and business continuity pressure
Service-level agreements raise the stakes even further. A public website may be only the visible tip of a larger dependency chain that includes APIs, customer portals, dashboards, identity services, and partner integrations. Procurement teams and auditors may care less about packets than about proof that you can keep serving customers under stress. Renewal conversations get harder when customers remember the outage more clearly than the root cause.
3. DDoS attacks as cover for other threats
Attackers also use DDoS as cover. While one team is busy restoring performance, another malicious workflow may be probing for exposed admin panels, stuffing credentials, or pushing phishing that looks more believable during confusion. Because of that, we never treat an availability incident as a standalone story until identity logs, endpoint telemetry, and change records say so. Noise on the edge can hide sharper tools in the middle.
Know your service, defenses, and traffic baseline
Before buying more products, we advise teams to understand what they are actually protecting. Good DDoS defense starts with a service map, a provider map, and a traffic baseline. Without those three views, even strong tooling produces noisy alerts and slow decisions.
1. Identify critical assets, dependencies, and bottlenecks
Critical assets are not just your homepage. In practice, the fragile points are often DNS, load balancers, login flows, APIs, origin servers, admin interfaces, payment callbacks, and third-party services that your application quietly depends on. Every one of those dependencies can become a bottleneck under malicious load. We like to ask a blunt question here: if one component slows down, what else breaks with it?
2. Understand upstream defenses from ISPs and cloud providers
Upstream defenses matter because your ISP, cloud provider, CDN, or mitigation vendor may already absorb part of the problem before it reaches you. Still, “included protection” can mean very different things in real life. Some providers offer always-on filtering, while others require manual escalation to a scrubbing service. From our standpoint, customers should know trigger points, support contacts, blackhole options, origin protection rules, and exactly which layers are covered by contract.
3. Monitor normal and peak traffic patterns
Normal traffic is your reference point. Seasonal peaks, marketing campaigns, search crawlers, API bursts, and time-of-day patterns all shape what healthy demand looks like. Once we know the baseline for request rate, bandwidth, latency, cache hit ratio, error rate, and geographic mix, abnormal behavior stands out sooner. That early clarity is priceless because DDoS response works best when the first alert already includes context.
How to detect a DDoS attack early

Early detection is one of the cheapest wins in DDoS defense. The faster a team sees the pattern, the more likely it is to preserve availability, trigger provider help, and avoid cascading failures. For that reason, we favor detection methods that combine telemetry, synthetic tests, and human reporting.
1. Traffic spikes, slow performance, and failed requests
Traffic spikes are the obvious clue, but the better signal is an abnormal relationship between traffic and user value. If requests surge while conversions, authenticated sessions, or cache efficiency drop, something is wrong. Slow page loads, worker exhaustion, rising queue depth, and a sudden concentration of repetitive requests against a small set of URLs can all appear before a full outage. By the time customers say the site is down, the infrastructure has usually been struggling for a while.
2. Timeouts, 503 errors, and outages across shared services
Timeouts, server errors, and region-specific failures often point to shared stress instead of an isolated bug. A flood may overload a reverse proxy, DNS path, cache tier, or authentication dependency and make several services look broken at once. That is why we tell teams not to stare only at the application dashboard. Network telemetry, CDN logs, WAF events, and provider status signals need to sit beside app metrics during triage.
3. Alerts from employees, providers, and monitoring systems
Alerts rarely come from one place. Employees may notice odd slowness in admin tools, providers may warn about attack signatures, and synthetic or real-user monitoring may catch rising latency long before executives hear about a problem. In our experience, the best organizations treat those signals as one shared incident thread rather than three separate conversations. Coordination beats volume when minutes matter.
How to prevent DDoS with attack surface reduction

When readers ask us how to prevent DDoS attacks, we often start with reduction before mitigation. The smaller the exposed surface, the fewer doors an attacker can test and the less traffic your origin must absorb. That makes every later control more effective.
1. Limit exposed ports, protocols, and unnecessary services
Unnecessary exposure is an attacker’s gift. Close unused ports, disable obsolete protocols, remove public admin panels, and restrict management services to trusted paths such as a VPN or dedicated jump host. On web workloads, we strongly prefer keeping origin servers reachable only from approved edge networks rather than from the open internet. If attackers can bypass your CDN or proxy and hit the origin directly, many expensive protections become decorative.
2. Use load balancing, geographic controls, and caching
Load balancing, caching, and geographic controls buy breathing room by reducing hot spots and shrinking the amount of origin work per request. Serve cached content whenever it is safe, and consider returning cached pages temporarily if the origin is struggling. Geographic rules should be precise, not panicked; challenge or rate-limit suspicious regions before you block broad swaths of real customers. Businesses care because these choices improve both security and everyday speed.
3. Distribute traffic with CDNs and Anycast networks
In an Anycast design, the same service address is announced from many edge locations, so requests are absorbed by the nearest or best path instead of by one central site. That distribution helps CDNs absorb bursts, serve static content closer to users, and keep attack traffic away from fragile backend systems. Even so, distribution is not magic. Unless the origin is locked down and the cache strategy is sensible, attackers can still force expensive misses or route around the edge entirely.
How to prevent DDoS with filtering and mitigation tools
After the attack surface is trimmed, filtering and mitigation tools become the active shield. Here, the goal is not just to block more traffic; it is to separate useful traffic from waste without punishing legitimate customers. Good tuning matters as much as good products.
1. Rate limiting, protocol filtering, and bot management
Rate limiting works best when it matches the behavior of the service being protected. Per-IP limits alone are blunt because carrier NAT and enterprise gateways can place many real users behind one address, so token-aware or endpoint-aware rules are often safer. On the protocol side, SYN cookies, fragment validation, and sensible connection thresholds help preserve device state under pressure. Add bot management on top, and you gain the ability to challenge suspicious clients, fingerprint automation, and reduce noisy traffic that tries to look human.
2. Web application firewalls for application layer protection
A web application firewall is especially useful against application-layer floods because it understands HTTP methods, headers, paths, cookies, and query patterns. Too many teams buy a WAF and assume the job is done. In practice, the strongest protection comes from custom rules around high-cost endpoints, trusted automation, and abuse patterns unique to the application. That extra tuning pays off when attackers mimic normal browsing behavior or hide behind cache-busting URLs.
3. Traffic scrubbing and blackhole routing when escalation is needed
Scrubbing services take the escalation path further by rerouting traffic through infrastructure built to filter floods at scale. Blackhole routing, by contrast, is a last-resort move that intentionally drops traffic to protect the rest of the network. We think every business should understand that tradeoff before an incident, not during one. Scrubbing aims to preserve availability; blackholing may sacrifice one target to save everything around it.
Infrastructure and hygiene practices that strengthen DDoS defense
Technology stacks that survive DDoS pressure usually share one trait: disciplined operational hygiene. Capacity, redundancy, endpoint security, and secure access practices all influence how gracefully a service fails or whether it fails at all. In our view, these basics deserve as much attention as headline mitigation tools.
1. Scale bandwidth and build redundancy across locations
Bandwidth helps, but raw capacity alone is not a strategy. Real resilience comes from spreading services across locations, removing single points of failure, and using front-end servers that can be duplicated quickly without carrying unique local state. Multiple regions, diverse providers, redundant DNS paths, and tested failover procedures reduce the chance that one saturated component knocks out the whole service. For businesses, redundancy is not overengineering when uptime carries contractual or revenue consequences.
2. Harden endpoints with updates, MFA, anti-malware, and backups
Updates, multi-factor authentication (MFA), anti-malware, and backups strengthen DDoS defense because attackers rarely stay confined to one tactic. If administrative access is weak, a noisy flood can distract a team while credentials are abused or systems are altered. Harden edge devices, patch internet-facing software, require MFA for administrative access, and keep clean backups or snapshots ready for recovery. Those steps will not absorb packets, but they do reduce the odds that a DDoS event turns into a broader compromise.
3. Train employees and use secure access practices such as VPNs
People matter more than many teams admit. Employees should know how to report suspicious slowness, how to avoid exposing management systems, and how to use secure remote access instead of opening services to the public internet. A VPN can protect administrator connections or remote staff sessions, which is useful, but it does not replace edge mitigation for a public website. In other words, secure access helps the operators; it does not magically shield the storefront.
How to choose the right DDoS protection provider
Choosing a mitigation partner is one of the most practical DDoS decisions a business makes. Price matters, of course, but so do architecture fit, response speed, operational visibility, and the provider’s willingness to help under real pressure. We recommend judging vendors the way you would judge a recovery team, not just a feature matrix.
1. Look for always-on mitigation, global capacity, and Anycast reach
Always-on mitigation is usually safer than on-demand activation because the first moments of a large attack can be the worst moments. Global capacity and broad Anycast reach also matter because a provider can only absorb what its network is built to handle. Ask where the edge sites are, how origins are shielded, whether mitigation is automatic, and how traffic is rerouted when trigger points are crossed. A pretty dashboard means very little if the network cannot catch the first punch.
2. Prioritize visibility, threat intelligence, and automated response
Visibility separates mature services from black boxes. Teams need logs, attack classifications, historical trends, alert hooks, and exports into central monitoring or a SIEM so mitigation data can be correlated with application behavior. Threat intelligence and automated response add another layer of value because they shorten the loop between detection and action. Frankly, we trust providers more when they help customers learn from attacks rather than merely announce that something was blocked.
3. Compare managed services, cloud scrubbing, on-premises tools, and hybrid options
Managed services suit organizations that want experts to tune and operate the defense for them. Cloud scrubbing offers elastic scale for public workloads, while on-premises appliances can be useful for private applications or environments that need local control. Hybrid models blend both and often make sense for regulated environments or complex enterprises. The right answer depends on traffic profile, compliance, internal talent, and how much control a team genuinely wants to keep.
How to prevent DDoS with a tested response plan
Even the best controls can be undone by confusion. A tested response plan turns scattered tools into coordinated action, which is essential when attack traffic, customer complaints, and leadership questions all arrive at once. We see this as the operational half of how to prevent DDoS attacks from becoming business crises.
1. Assign roles, contacts, and escalation paths
Clear roles prevent drift. Someone should own incident command, someone should manage network and provider coordination, someone should validate application health, and someone should handle customer and executive communication. Contact lists need after-hours paths, provider escalation numbers, and authority boundaries for fast decisions. Without that structure, teams lose precious time debating who is allowed to act.
2. Prepare stakeholder communications and recovery checklists
Communication plans deserve the same care as technical playbooks. Customers, employees, partners, and executives all want different levels of detail, and each group reacts badly to silence. A public status update should explain impact and next steps without turning into a packet-level lecture. Recovery checklists should spell out what to verify before declaring the incident over: origin reachability, cache behavior, error rates, queue depth, payment flows, authentication, and any temporary rules that must be rolled back.
3. Run drills, simulations, and ongoing mitigation validation
Drills expose weak assumptions before attackers do. Tabletop exercises help teams practice decisions, while controlled simulations validate rate limits, failover logic, and provider response paths. We like recurring tests because mitigation quality drifts as applications change, traffic patterns shift, and teams rotate. If the runbook has not been exercised in a long time, it is a theory, not a capability.
What to do after a DDoS attack
Once the traffic subsides, the real work is not over. Post-incident analysis turns a painful event into a stronger design, while a shallow recovery nearly guarantees a repeat surprise later. For us, the postmortem is where resilience actually compounds.
1. Analyze the attack method, duration, and affected assets
Start by documenting what happened at each layer: entry path, attack vectors, targeted assets, mitigation steps, and time to recovery. Then look for the first control that bent under pressure. Was the origin exposed, the rate limit too loose, the baseline incomplete, or the provider escalation too slow? That sequence matters because the earliest failing layer often reveals the cheapest fix.
2. Measure financial, operational, and reputational impact
Next, translate the incident into business language. Measure lost transactions, delayed operations, support volume, SLA exposure, extra provider costs, and the likely reputational effect on customers or partners. Executives fund resilience faster when the outcome is framed as interrupted business value rather than as abstract packet loss. We have seen that lesson land again and again.
3. Update controls, provider expectations, and recovery plans
Finally, update controls, contracts, and recovery plans while the memory is fresh. Tighten rules, remove direct-origin exposure, refine alerts, raise provider expectations, and document which mitigations were useful versus noisy. Just as important, feed the lessons back into architecture and training. A DDoS incident should leave behind better defaults, not just a closed ticket.
FAQ

Below are the short answers we give most often when customers ask us about DDoS prevention. The common thread is simple: no single tool wins on its own, but layered design dramatically improves your odds.
1. How is a DDoS attack prevented?
A DDoS attack is prevented through layers: reduce exposure, distribute traffic, filter abusive patterns, and rehearse the escalation path. At 1Byte, we view prevention as a mix of architecture, tooling, and operations rather than one appliance or one switch.
2. What is the best way to prevent a DDoS attack?
The best approach is usually always-on edge mitigation paired with a locked-down origin and a tested response plan. Different businesses need different tuning, but the winning pattern is consistent: absorb at the edge, inspect intelligently, and keep the origin hidden and scalable.
3. Does a VPN prevent DDoS?
No, a VPN does not prevent DDoS against a public website by itself. What it can do is protect administrator access or hide the direct address of internal services, which is valuable for secure operations. Public web traffic still needs CDN, WAF, rate limiting, provider mitigation, or scrubbing capacity.
4. Can a firewall stop a DDoS attack?
A firewall can stop some smaller or simpler attacks, especially when rules are well tuned at the application layer. Massive volumetric floods are different because they can exhaust bandwidth or upstream devices before a traditional firewall gets a fair chance to inspect much of anything. That is why we treat firewalls as one layer, not the whole answer.
5. What are the signs of a DDoS attack?
Common signs include unusual traffic spikes, slow performance, rising latency, repeated timeouts, server errors, heavy hits on a few URLs, regional outages, and alerts from providers or monitoring tools. Strange gaps between traffic volume and real user activity are also telling. If the numbers climb while the business outcome drops, we start asking hard questions fast.
6. Is DDoS illegal in the US?
Yes. The FBI states that Participating in Distributed Denial of Service attacks (DDoS) and DDoS-for-hire services is illegal in the United States. In practical terms, that means launching an attack, buying booter or stresser services, or helping operate them can carry serious criminal risk. For case-specific advice, speak with a qualified attorney.
How 1Byte supports website resilience as a cloud computing and web hosting provider

At 1Byte, we do not pretend any host can promise perfect immunity. What we can do is help customers build a cleaner starting point, choose the right hosting model, and avoid the design shortcuts that make DDoS incidents worse. That foundation matters more than flashy claims.
1. Build a secure foundation with domain registration and SSL certificates
Domain registration and SSL certificates do not stop floods on their own, but clear ownership and strong account protection matter during an incident. Protected registrar access, careful DNS record management, and well-managed SSL certificates keep the front door under your control when changes need to happen quickly. We encourage customers to start there because resilience is much harder when the basics are messy.
2. Launch and manage websites with WordPress hosting and shared hosting
For WordPress hosting and shared hosting, day-to-day discipline matters just as much as raw infrastructure. Caching, plugin hygiene, version updates, account isolation, and sensible resource limits all influence how gracefully a site behaves under abnormal load. We help customers launch quickly, but we also push for configurations that stay maintainable when real traffic, good or bad, arrives.
3. Scale with cloud hosting and cloud servers from an AWS Partner
Cloud hosting and cloud servers give growing businesses more room to scale, segment workloads, and integrate stronger network controls. As an AWS Partner, we think in terms of architecture, not just virtual machines: load balancing, redundancy, origin protection, autoscaling patterns, logging, and recovery design. That is the kind of environment where layered DDoS defense becomes practical rather than theoretical.
Final thoughts on how to prevent DDoS attacks
To us, how to prevent DDoS attacks comes down to one idea: do not ask one control to solve a multi-layer problem. Reduce the surface, distribute traffic, filter aggressively but intelligently, secure admin access, and rehearse the response before the pressure arrives. When those layers work together, availability stops depending on luck.
If you are reviewing your stack this quarter, start with a few hard questions: can attackers reach the origin directly, do you know your normal traffic baseline, and can your team escalate mitigation quickly when pressure spikes? Any uncertain answer is your next project.