
- What Is a Search Engine
- How Does a Search Engine Work Step by Step
- How Search Engines Discover and Crawl Content
- How the Search Index Stores and Organizes Pages
- How Search Engines Rank and Serve Results
- Why Pages Do Not Appear in Search Results
- Why Understanding How a Search Engine Works Improves SEO
- Search Engines and Browsers Are Not the Same
- FAQ
- How 1Byte Supports Search-Friendly Websites
- Conclusion: How a Search Engine Works from Discovery to Ranking
When people ask “how does a search engine work,” they are really asking how software discovers pages, interprets meaning, and decides what deserves attention first. At 1Byte, we think the cleanest answer is also the most useful one: search is a pipeline, not a mystery. Behind that simple search box sits a system that finds URLs, builds an index, and then ranks documents against intent, context, and usefulness. For businesses, that means SEO is less about tricks and far more about making a site easy to reach, easy to understand, and worth showing.
From a market perspective, search still matters enormously for online visibility. Statista reported Google held 89.62 percent market share across all devices worldwide as of March 2025, which is why understanding search mechanics is still foundational for most public websites.
What Is a Search Engine

At 1Byte, we usually explain a search engine as a retrieval system built for web-scale discovery. It is not just a website with a text box, and it is not simply browsing the live internet on demand. Instead, it relies on previously discovered pages, stored representations of those pages, and ranking systems that try to match the best answer to the query in front of them.
1. A searchable system for finding information on the web
In plain language, a search engine helps people find relevant information without needing to know the exact URL beforehand. Rather than scanning the whole web from scratch every time someone searches, it works from a large stored index of pages and signals gathered earlier. That design is what makes search feel instant to users, even though the underlying system is continuously discovering, processing, and refreshing content in the background.
2. The search index and algorithm behind every query
Google’s own documentation describes three stages: crawling, indexing, and serving search results, and we think that model is the clearest starting point for beginners. The index acts like a structured memory of known pages, while ranking systems evaluate which stored pages appear most useful for a given query. Put differently, the index answers “what exists,” and the algorithm answers “what belongs here now.”
3. Different result types such as web, image, video, and news
Search results are not all the same shape, and that detail matters more than many site owners expect. A single query might produce standard text results, image results, video results, local packs, or news-oriented surfaces depending on what the engine thinks the user wants. Google even uses examples where a query like “bicycle repair shops” tends to trigger local-style results, while a more visual query like “modern bicycle” leans toward image-heavy results.
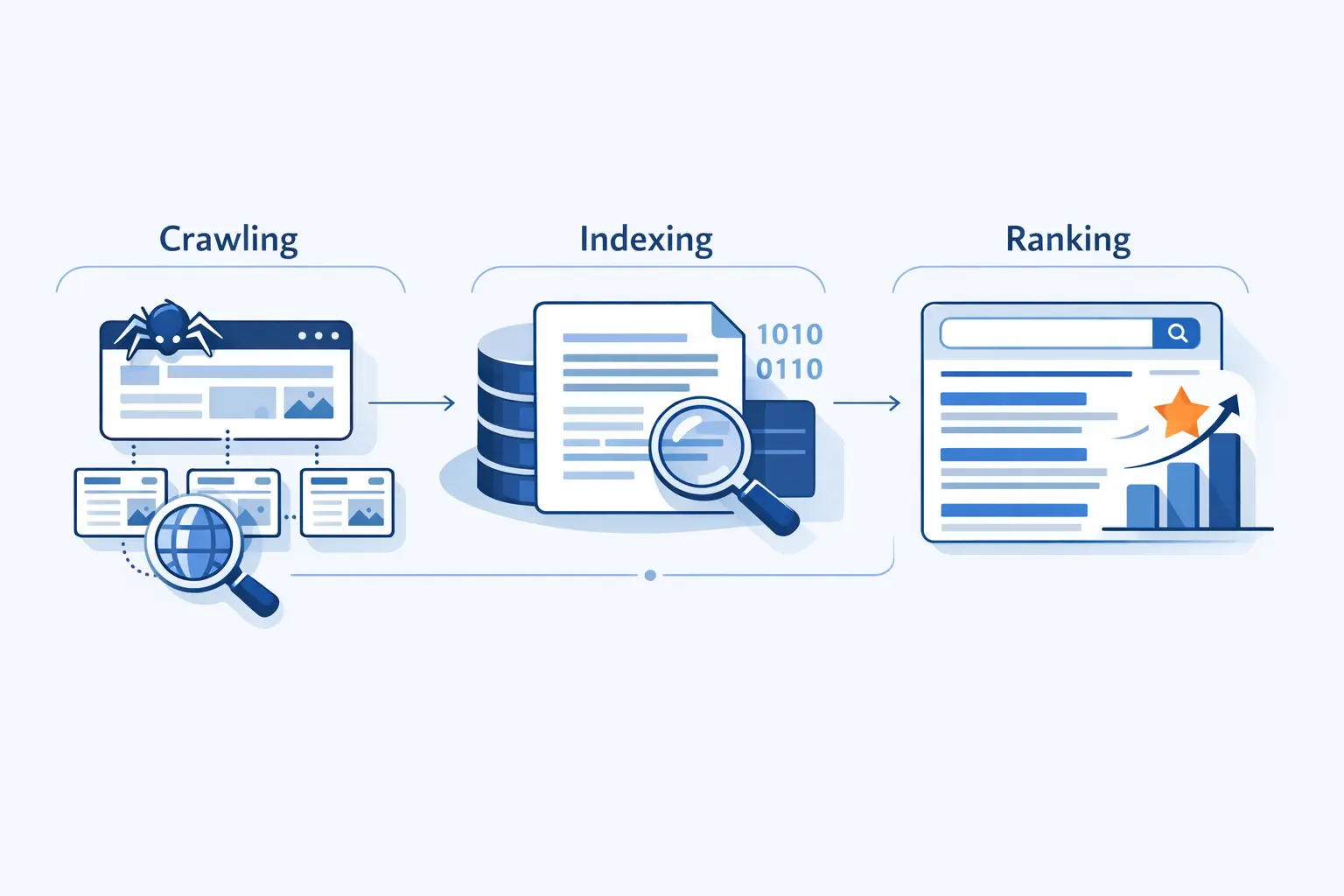
How Does a Search Engine Work Step by Step
We find that most confusion disappears once people stop treating search as one big monolith. In practice, the process is sequential: engines first discover content, then interpret and store it, and only after that decide whether it should appear for a specific query. Each stage has its own failure points, which is why a page can be perfectly written and still never show up if discovery or indexing breaks first.
1. Crawling discovers new and updated pages
Crawling is the discovery phase. Search engines find URLs through links, previously known pages, and submitted sitemaps, then fetch those pages to see what is there. Because there is no master list of every page on the web, engines have to keep revisiting known URLs and looking for new ones at the same time. That is why fresh internal links and clean site architecture matter so much for new content.
2. Indexing analyzes content, metadata, images, and video
Once a page is fetched, the engine tries to understand it. During indexing, it analyzes text, titles, alt text, images, videos, and other page signals, then decides whether the page is distinctive enough and useful enough to store. Engines also cluster duplicates and choose canonical versions, which means several similar URLs may collapse into one preferred result. For us, this is the point where page clarity beats raw publishing volume every time.
3. Serving and ranking return the most relevant results
Serving is the moment users actually experience, but it depends entirely on the earlier work. The engine searches its index for candidates, weighs relevance and quality, and then reshapes the final page based on factors such as query intent, language, location, and device. A result set is therefore not just “the best page on the web”; it is the best available page for that user, in that context, at that moment.
How Search Engines Discover and Crawl Content
Discovery is where technical SEO earns its keep. Search engines cannot evaluate a page they do not know about, and they cannot process a page they cannot access. From our perspective, crawlability is the first gate every public page has to pass, which makes link structure, server behavior, and access rules business-critical rather than merely “technical.”
1. Links, sitemaps, and URL discovery
Internal links are often the main roads crawlers follow. A category page can expose a new article, a product hub can expose a new SKU, and a sitemap can give engines a cleaner list of URLs you want discovered. None of that forces indexing, but it does improve discovery and prioritization. For publishers, news sitemaps add another layer by helping engines understand that certain URLs are fresh news content rather than ordinary archive pages.
2. Crawlers, bots, and JavaScript rendering
Modern crawling is not limited to downloading raw HTML. Google says Googlebot runs any JavaScript it finds, which is helpful, but we still advise keeping critical content visible without relying on fragile client-side behavior. In practice, not every crawler or engine handles rendering with the same depth or speed, so shipping important text, links, canonicals, and metadata in the initial HTML remains the safer path for businesses.
3. robots.txt, server responses, and crawl access
robots.txt matters, but the standard itself says it is not a form of access authorization, which is why private content needs real access control rather than a polite request file. Server responses matter just as much: repeated errors can slow crawling, and pages behind logins usually stay out of reach for ordinary web crawlers. In other words, discovery depends on permission, stability, and response quality all at once.
How the Search Index Stores and Organizes Pages

The search index is not a scrapbook of full pages pasted into one giant folder. Instead, it is a structured system for storing meaning, relationships, page type, duplication signals, and many kinds of relevance context. That distinction matters because ranking rarely depends on one visible page element alone; it depends on how the engine has interpreted the whole document and its role within the wider web.
1. Keywords, content type, freshness, and engagement signals
At a practical level, engines organize pages around terms, topics, page purpose, media type, and recency cues. They also collect signals related to language, locality, and usability, then use those signals later when ranking results. Some marketers loosely call parts of this bucket “engagement signals,” but in our view the safer mental model is broader: search engines are trying to estimate usefulness and satisfaction, not reward vanity metrics in isolation.
2. Metadata, structured data, and canonical tags
Metadata helps engines interpret the page, structured data can make a page eligible for richer search appearances, and canonical tags help consolidate duplicates. Google documents that rel=”canonical” link annotations are a strong signal when it chooses a preferred URL, which is why ecommerce variants, faceted navigation, and filtered pages need deliberate canonical strategy. When those signals line up, search engines waste less time guessing and spend more time understanding.
3. Why some pages are crawled but not indexed
A crawled page is not automatically an indexed page. Search engines may fetch a URL and still decide not to keep it because the content is low quality, too duplicative, hard to interpret, blocked by indexing rules, or simply not useful enough compared with other versions. We see this often on sites with thin category stubs, parameter-heavy duplicates, or templates that technically load but contribute little distinct value.
How Search Engines Rank and Serve Results
Ranking is where most of the mythology creeps in. Yet the underlying goal is straightforward: return the most relevant and useful result set possible for the query at hand. Search engines use automated systems and many signals to make that judgment, which means ranking is always contextual, comparative, and probabilistic rather than absolute.
1. Relevance and search intent come first
Relevance is the first filter, and intent sharpens it. An informational query wants explanation, a local query wants nearby options, and a product query may want comparison, reviews, or pricing context instead of a general article. This is why a beautifully optimized page can still underperform when it targets the wrong intent. We often tell clients that alignment beats embellishment.
2. Quality, authority, and page usefulness influence rankings
After relevance, engines still have to decide which matching pages deserve trust. Google’s documentation emphasizes helpful, reliable, people-first content and also notes that good page experience supports ranking success, especially when many relevant options exist. That combination matters for businesses because quality is not just about writing; it is also about clarity, trust signals, usability, and whether the page genuinely solves the searcher’s problem.
3. Location, language, device, and query type reshape results
Two users can type nearly the same words and still see different results. Search engines reshape rankings based on geography, interface language, device type, and the kind of query being asked, which is why local businesses, multilingual brands, and mobile-heavy sites need tailored SEO thinking. For us, this is the point where “average rankings” become a blunt instrument; context is doing far more work than one position number suggests.
4. Organic rankings are separate from paid ads
Organic results and paid ads are different systems. Google explicitly says it does not accept payment to rank pages higher in organic search, so ad spend may buy visibility through advertising placements but it does not buy organic placement inside the ranking system itself. Businesses that blur those two channels usually misdiagnose the real problem and overspend in the wrong place.
Why Pages Do Not Appear in Search Results

When a page disappears, site owners often assume the ranking algorithm suddenly “hated” it. In reality, the first question should be more basic: was the page crawled, was it indexable, and did the engine consider it eligible to serve at all? That diagnostic order saves time because many missing-page problems are accessibility or indexing issues, not competitive ranking failures.
1. Noindex tags, blocked resources, and login walls
A page can vanish simply because it tells search engines to stay away. A noindex directive, inaccessible resources, or a login requirement can stop a page from entering or remaining in search. Google also warns that if noindex is present in the original code, JavaScript-based attempts to remove it later may not work reliably, which is one more reason to keep index-control rules simple and explicit.
2. Low quality, thin content, and duplicate pages
Search engines do not need every URL you publish. Thin pages, near-duplicates, and weak doorway-style content can be crawled yet still filtered out, merged into another canonical, or ignored because a stronger page already satisfies the same need. In our experience, sites often lose visibility not because they publish too little, but because they publish too much of the same thing with too little differentiation.
3. 404 pages, 500 errors, and other crawl issues
Status codes also shape visibility. A successful response may be considered for indexing, but that still does not guarantee inclusion, while clear client or server errors can block or delay progress altogether. Error-like content on a technically successful URL can even produce soft-404 style treatment, which is why “the page loads in my browser” is not the same thing as “the page is healthy for search.”
Why Understanding How a Search Engine Works Improves SEO

At 1Byte, we see one recurring pattern: teams improve faster once they understand the machinery underneath SEO. Search stops feeling superstitious and starts feeling operational. That shift is powerful because it turns vague goals like “rank higher” into concrete jobs such as fixing access, improving page usefulness, clarifying canonicals, or strengthening internal links.
1. Technical SEO helps crawlers reach important pages
Technical SEO gives search engines a cleaner route through the site. Good internal linking, sensible canonicals, working status codes, robots rules that do not block essential content, and well-maintained sitemaps all help crawlers spend time on the pages that matter most. Put another way, technical SEO reduces ambiguity, and reduced ambiguity usually makes indexing and ranking systems more confident.
2. Helpful content and internal links strengthen relevance
The business upside is not theoretical. Google’s Saramin case study reported a 102% Increase Year-Over-Year (YOY) in organic traffic from Google Search during the hiring season in 2019 after the company cleaned up weak metadata, used canonical URLs, and applied relevant structured data. We do not read that as a promise for every site, but we do see it as a strong real-world example of what happens when technical clarity and useful content reinforce one another.
A similar lesson shows up in Google’s MX Player case study, where better video discoverability followed the use of structured data and frequent video sitemap submission. For us, the takeaway is simple: once search engines can clearly understand what a page is and why it exists, they are far better positioned to surface it in the right search features.
3. Search Console supports monitoring and troubleshooting
When a page underperforms, Google Search Console often gives the fastest useful clues. Google says the URL Inspection tool provides the current index status of website pages, which is exactly why we reach for it when someone says a page is “not ranking.” Sometimes the page is not ranking at all; other times it is not indexed, not accessible, or not being served the way the team assumed.
Search Engines and Browsers Are Not the Same
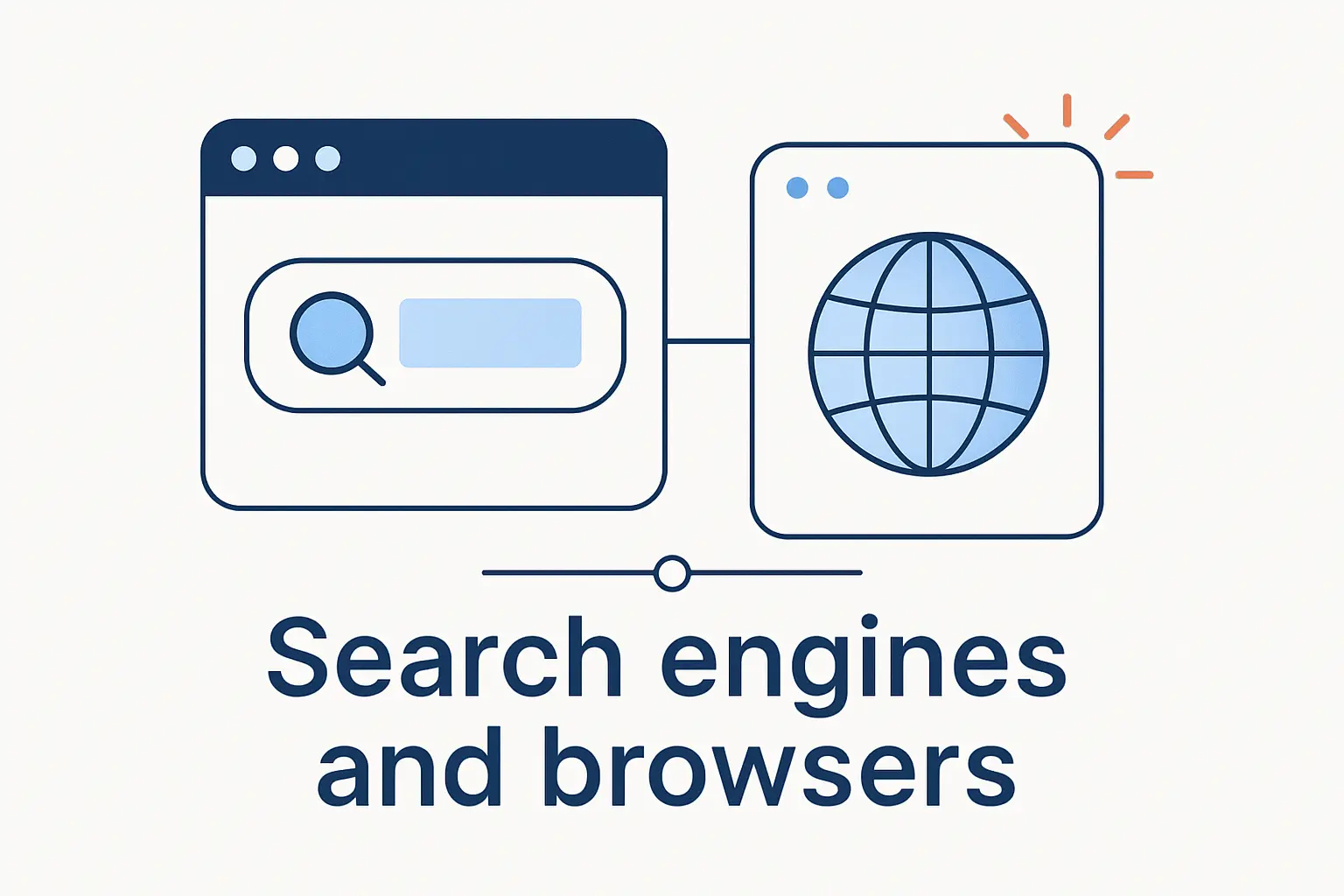
This confusion is everywhere, and honestly, we understand why it happens. People often open a browser, land on a search engine home page, and experience both as one seamless thing. Under the hood, though, they do different jobs, and that distinction matters when you are troubleshooting visibility, performance, or access problems.
1. What a search engine does
A search engine discovers public pages, builds an index, and ranks possible answers for queries. Its job is organizational and evaluative: find documents, understand them, and decide which ones best match the searcher’s intent. If a site is missing from search, the issue usually lives in this ecosystem of discovery, indexing, or ranking rather than in the browser itself.
2. What a browser does
A browser is the application that retrieves and displays web pages for the user. It renders HTML, CSS, and JavaScript, follows hyperlinks, and gives people tabs, address bars, and navigation controls. Chrome, Safari, Edge, and Firefox are browsers; Google Search and Bing are search engines that can be visited inside those browsers.
3. Why users often confuse the two
Default home pages and built-in search boxes blur the line. Because a browser may open directly to a search engine, many users understandably think the software window and the search service are the same product. For businesses, the practical lesson is this: a browser problem affects page rendering for users, while a search engine problem affects discovery and visibility before many users ever arrive.
FAQ

Below are the short answers we would give most site owners before opening a full audit. Each answer is simple on purpose, but each points back to the same core framework: discovery, understanding, and usefulness.
1. What are crawling, indexing, and ranking
Crawling is how a search engine discovers and fetches a page. Indexing is how it analyzes and stores what the page is about. Ranking is how it decides whether that page should appear for a particular query and where it should appear relative to other candidates.
2. Why is my page not showing up in Google Search
The usual reasons are straightforward: the page may be blocked, tagged with noindex, hidden behind a login, returning an error, judged too duplicative, or simply not strong enough to earn a visible placement. Before worrying about rank, check accessibility and index status first.
3. How do robots.txt and sitemaps affect search engines
robots.txt tells crawlers which paths they may or may not fetch, while sitemaps help engines discover important URLs more efficiently. Neither file guarantees ranking, and robots.txt is not the right tool for removing already indexed pages from results.
4. Can search engines crawl pages behind a login
Generally, public web crawlers cannot access normal login-protected content. If a page requires authentication, the engine usually cannot fetch the full content in the same way a signed-in user can. That is why public landing pages and private application areas need different visibility expectations.
5. Is Google always 100 percent right
No. Search systems are automated judgment systems, not perfect librarians, and Google itself says indexing is not guaranteed even for pages it processes. In our view, the practical response is not to expect perfection but to reduce ambiguity so the engine has fewer chances to misunderstand your site.
6. What is the number 1 search engine
Google remains the clear number one search engine worldwide. Current StatCounter data for March 2026 still shows Google leading global search by a wide margin, and earlier Statista reporting points in the same direction.
How 1Byte Supports Search-Friendly Websites

At 1Byte, we approach search friendliness as an infrastructure issue as much as a content issue. A site needs discoverable URLs, stable delivery, secure connections, and an architecture that does not fight the crawler at every turn. That is why we care about the hosting layer, the domain layer, and the operational layer together rather than treating SEO as something that happens only inside a CMS editor.
1. 1Byte domain registration and SSL certificates for a secure foundation
We support the basics that every public site needs first: domain registration, domain management, and SSL certificates for secure delivery. A clean domain setup makes URL governance easier, while HTTPS builds user trust and supports a safer browsing experience. From our standpoint, that foundation is not glamorous, but it is the starting block for every crawlable and credible website.
2. 1Byte WordPress hosting and shared hosting for reliable site performance
For teams that want simpler publishing and dependable day-to-day delivery, we also provide WordPress hosting and shared hosting options. Reliable hosting reduces the odds of avoidable crawl interruptions, while a smoother publishing environment makes it easier to keep important content updated, linked, and technically clean. In our experience, a stable platform gives marketing teams more room to focus on content quality instead of firefighting infrastructure quirks.
3. 1Byte cloud hosting and cloud servers from an AWS Partner
As an AWS Consulting Partner, we also think in terms of scalability and long-run architecture, not just basic uptime. Our cloud hosting and cloud server options are meant for businesses that need more flexibility, stronger operational control, or a clearer route to modern cloud workloads. When traffic grows, applications spread across services, or migration becomes part of the roadmap, that broader cloud capability becomes especially important.
Conclusion: How a Search Engine Works from Discovery to Ranking
A search engine works by discovering pages, understanding them, storing what matters, and then choosing which results best satisfy the searcher’s intent. At 1Byte, we think that is the most useful frame for both beginners and business owners because it turns SEO from folklore into a sequence of visible systems: crawlability, indexability, and usefulness. Once you see those layers clearly, diagnosing weak visibility becomes much less intimidating.
If you want a practical next step, pick one important page on your site and audit it in that exact order: can crawlers reach it, can engines index it, and does it truly deserve to rank for the query you want? That one exercise often reveals more than hours of guesswork.